Recurrent Neural Network Algorithms Overview
Introduction
Frequently hearing about RNNs while having no clue what they are? This article is made for you to understand Recurrent Neural Networks and to come across their different algorithms.
Recurrent Neural Networks (RNN), first proposed within the 1980s, brought adjustments to the original structure of neural networks and enabled them to process sequences of data.
RNNs have been used successfully for several tasks involving sequential data including machine translation, sentiment analysis, image captioning, time-series forecasting, etc.
Many well-known RNN algorithms are brought to the table in this article: Simple RNN, LSTM, GRU, Bi-LSTM, and Encoder-Decoder RNN.
Keywords
Artificial Neural Networks – Recurrent Neural networks – Hidden States – LSTM – Memory – Bidirectional LSTM – Gating – GRU – Encoder – Decoder
Artificial Neural Networks (ANNs)
Artificial Neural Networks (ANNs) are supervised learning computing systems containing a large number of simple interconnected units called neurons, inspired by the neurons in biological brains. Each artificial neuron has inputs and produces an output which can be sent to multiple other neurons.
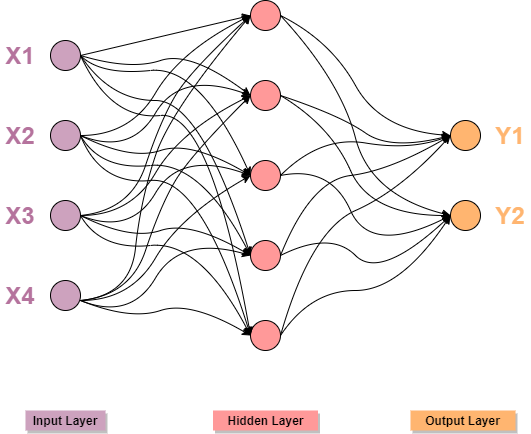
The image shown below depicts an ANN.
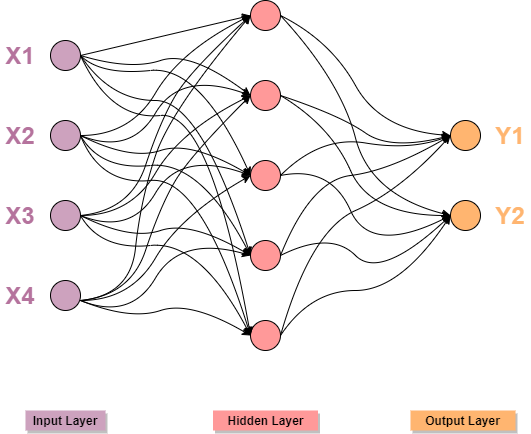
Simple Artificial Neural network with one hidden layer
Each node within the hidden layer processes the inputs received by the input layer through activation functions, and it passes the output to the next hidden layer till the output layer is reached and the output of the entire network is generated.
As the number of layers rises, it increases the complexity and the depth of the network, and empowers it to provide various levels of data representation and feature extraction, stated as “Deep Learning”.
ANNs with recurrent connections are called Recurrent Neural Networks (RNNs).
Recurrent Neural Network: General ideas
Recurrent Neural Networks constitute a class of ANNs that helps them handle input data that is sequential in nature. As examples, we can state a text, a speech recording, or a video that has multiple events that occur one after the other, and understanding each of them requires analyzing and remembering the past events.
A Recurrent Neural Network works on the principle of accepting a series of inputs, adding additional layers of comprehension on top of them, feeding the obtained results back into the network to be used to process future input.
It’s characterized by its looping mechanism which allows the creation of a sequential memory within the network.
It keeps track of previously processed information and uses it to influence future outputs.
What can Recurrent Neural networks do?
Some of the most significant applications of RNNs involve Natural Language Processing (NLP), the branch of artificial intelligence enabling computers to make sense of written and spoken language.
For instance, an RNN can capture the structure of a large body of text, and write additional text in the same style. It works by predicting the most suitable next character(s), word(s), or sentence(s) … in the generated text. Machine Translation is another prime use of RNNs in NLP, where the input is a sequence of words in the source language, and the model attempts to generate matching text in the target language.
RNN for machine translation (from English to Chinese)
Other NLP applications include Speech Recognition, Sentiment Analysis, Text Classifications, Text Summarization, Chatbots …
RNNs are capable also of generating image descriptions by identifying important features in an input image and generating an associated descriptive text. Any Time Series Forecasting problem can be solved by RNNs, especially when it comes to Multivariate Time Series where an ability to detect complex patterns from past data is needed.
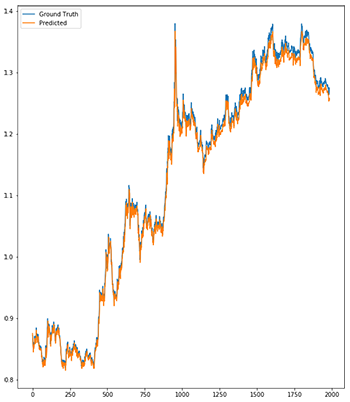
Currency exchange rates predictions (orange) using LSTM RNN by Neelabh Pant (2017)
Recurrent Neural Network algorithms
Simple RNN
A simple recurrent neural network is a multi-layered neural network, composed of input, hidden, and output layers. The point is that one hidden block doesn’t only receive its corresponding input at a specific time t, rather, the previous hidden state is fed as input too.
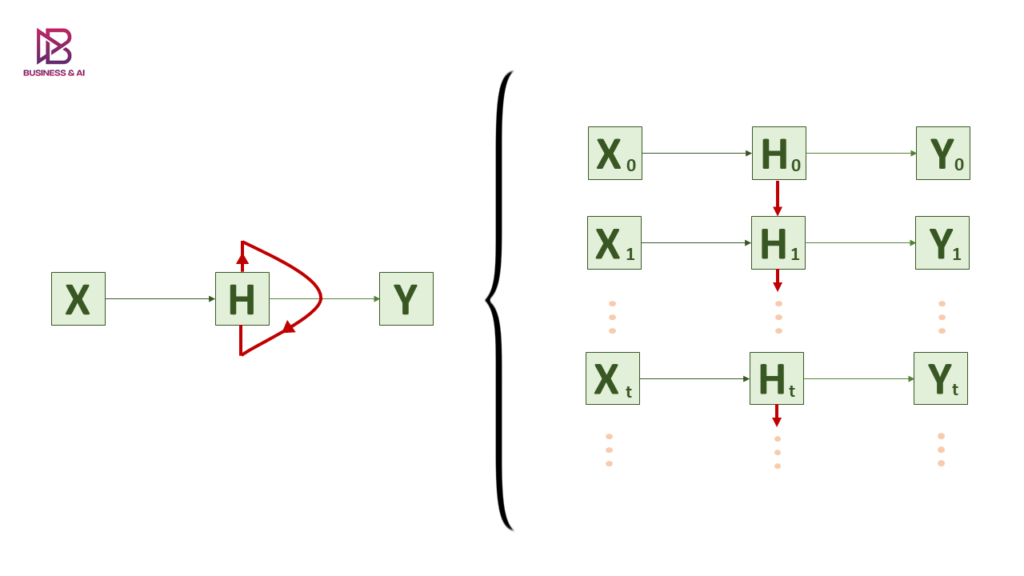
Unrolled RNN
The illustration above shows the folded and unfolded representation of the RNN in time. A part of the input sequence is given as input at each time step (X0, X1, … , Xt).
The H block is the principal block of the network where the looping mechanism is put into emphasis as it’s mostly clear in the folded version of the RNN.
The unfolded illustration shows in detail how the H block receives at each time step t the input at time t along with its output from the previous time step t-1.
Then, it passes its input to an activation function within the block and generates the appropriate output at time step t.
Long-Short Term Memory (LSTM)
In the late 1990s, German researchers Hochreiter and Schmidhuber proposed Long Short-Term Memory (LSTM), which helps an RNN retain information, and learn dependencies over a longer period of time.
While a basic RNN block has a few operations internally, an LSTM is considered a bit more complicated.
The LSTM has the ability to carefully control information passed to the cell state, via some structures called gates. The cell state carries the relevant information from the earlier time steps to later time steps, which alleviates the effects of short-term memory. Gates are meant to optionally let information through, they decide which information is allowed on the cell state and which information is thrown away.
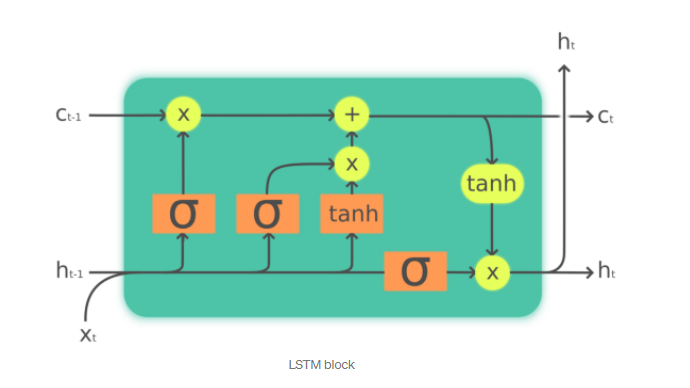
LSTM block structure (By Pedro Torres Perez)
Gated Recurrent Unit (GRU)
A gated recurrent unit model is basically another variant of RNNs bringing some enhancements to LSTMs: Simpler structure characterized by fewer gates, hence, faster training. It was introduced by Cho et al. in 2014 to mitigate the short-term memory issue using the gating mechanism, and it has achieved satisfying results since then.
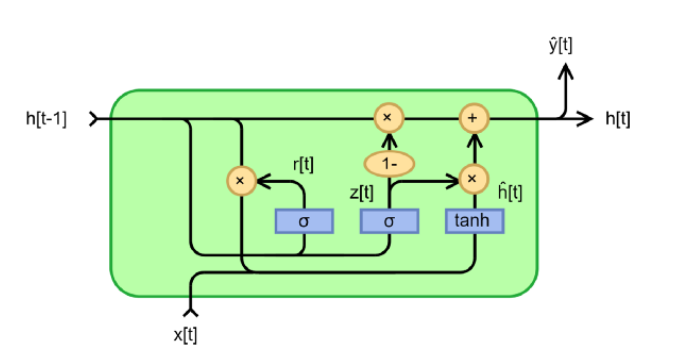
GRU block structure (By Pedro Torres Perez)
Bi-directional LSTM (Bi-LSTM)
A bi-directional LSTM is designed in a way that it preserves information from the past as well as from the future to predict current information.
It is based on understanding the whole context and looking at the big picture to make better predictive results.
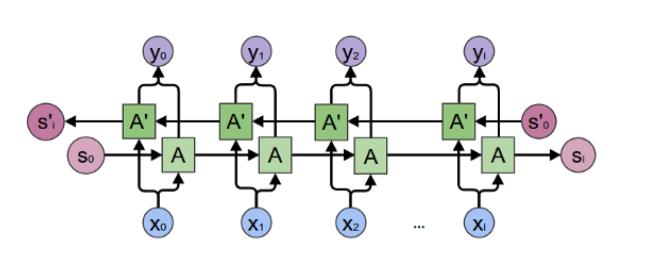
Bi-directional LSTM (By Raghav Aggarwal)
As shown in the figure, it’s simply a couple of LSTMs working in opposite directions and combining their outputs at each time step, which allows both the forward and backward processing of information.
Encoder-Decoder RNN
The encoder-decoder model with recurrent neural networks involves sequence to sequence learning and can especially be used for Machine Translation tasks.
The approach is based on two RNN models, each being the encoder and the decoder.
The encoder receives the input sequence at specific time steps and generates information as internal state vectors to be used by the decoder to make accurate predictions.
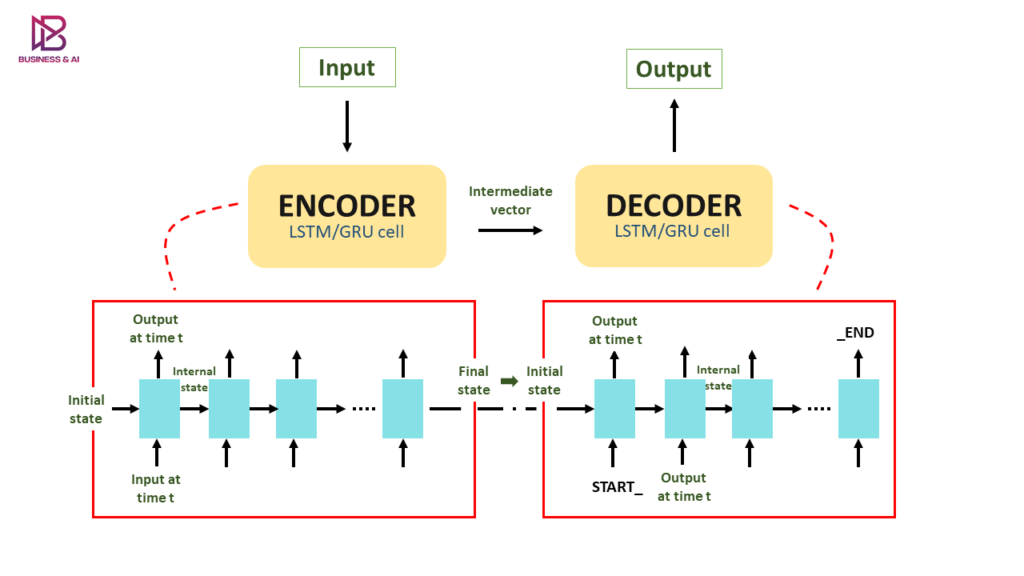
Encoder-decoder RNN architecture
Conclusion
Recurrent Neural Networks enable us to model time-dependent and sequential data problems, such as time series forecasting, machine translation, and text generation. However, RNNs often fail to achieve high accuracies, as they are not the best choice for learning long-term dependencies.
Because of their special architectures, a variety of models are doing tremendously well and are widely used, replacing simple RNNs in most of their major areas.
Stay tuned to learn more about every single algorithm in our future articles.
Abbreviations
- ANN – Artificial Neural Network
- RNN – Recurrent Neural Network
- NLP – Natural Language Processing
- GRU – Gated Recurrent Unit
- Bi-LSTM – Bi-directional LSTM
References
- https://medium.com/@raghavaggarwal0089/bi-lstm-bc3d68da8bd0
- https://medium.com/analytics-vidhya/machine-translation-encoder-decoder-model-7e4867377161
- https://medium.com/@raghavaggarwal0089/bi-lstm-bc3d68da8bd0
- https://www.researchgate.net/publication/322243714_Recent_Advances_in_Recurrent_Neural_Networks